Help > Tutorials > Woordvarianten
Woordvarianten
(Met dank aan: Nicoline van der Sijs)
Voor dit eerste tutorial proberen we het heel simpel te houden. We gaan de verschillende mogelijkheden van Nederlab verkennen met de meest simpele query die we kunnen bouwen.
Stap 1
Ga naar ‘Zoeken’, en blijf op ‘Eenvoudig zoeken’. Bij deze functie is het mogelijk om op woorden te zoeken, niet op verrijkingen. Het is dus niet mogelijk om te zoeken op ‘paard’, en daarbij automatisch ‘paarden’, ‘paardje’, etc. er allemaal makkelijk bij te krijgen. Toch is er hiervoor een oplossing bedacht. Typ bij ‘woord’ het woord ‘paard’ in, en vink vervolgens het vakje ‘Varianten inbegrepen’ aan. En zoeken maar.

Stap 2
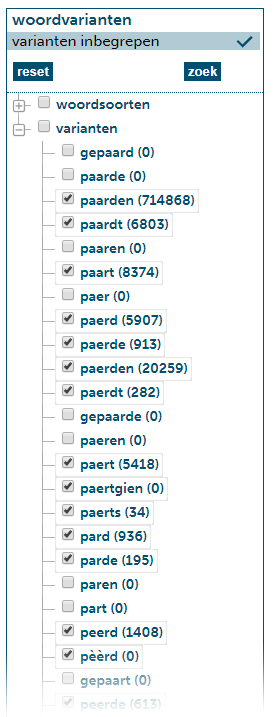
We hebben nu dus gezocht op het woord ‘paard’ en alle varianten die de zoekmachine daarbij kan vinden. Helaas is dit niet zo nauwkeurig als een sortering op lemma, maar we kunnen nu wel teksten doorzoeken die geen lemmadefiniëring hebben. Er moet echter nog wel wat gebeuren voordat de resultaten onderzoekbaar zijn. Scroll naar onderen en houdt het menu aan de linkerkant in de gaten. Wanneer het kopje ‘Woordvarianten’ in zicht komt verschijnt er een lijst met alle varianten die de zoekopdracht heeft meegenomen. Er zitten woorden bij die niks te maken hebben met ‘paard’, maar dit is onvermijdelijk. Gelukkig kun je hier makkelijk aan- of uitvinken wat je mee wil nemen. Doe dat zoals je instinct het je zegt, en klik dan op ‘Zoek’. Eventueel kun je ook woordsoorten aanvinken, maar die werken alleen wanneer een collectie verrijkingen heeft.
Stap 3
Afgezien van het individueel bekijken en archiveren van de resultaten is het nu vooral mogelijk om interessante statistieken te bekijken. In deze stap nemen we een kijkje bij het kopje ‘Visueel overzicht’. Hier krijgen we in de vorm van een verzameling cirkeldiagrammen mogelijk interessante informatie te zien, afhankelijk van je onderzoeksvraag. Niet alleen krijg je een overzicht van de collecties waaruit je resultaten hebt gehaald – wat voor een vervolgopdracht erg nuttig kan zijn – maar er is ook een overzicht van genre, categorie, en zelfs taal. Hou in gedachten dat niet alle collecties en documenten gespecificeerd hebben welk genre of categorie ze zijn. Tot slot is er een cirkeldiagram die laat zien hoeveel procent van de gevonden documenten verrijkingen hebben en hoeveel procent niet. In dit geval is het overgrote deel niet verrijkt.
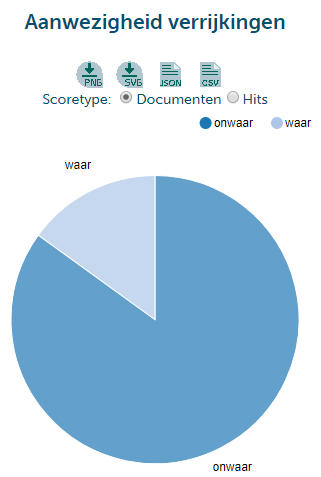
Het voordeel van zoeken op woordvariaties is dat je deze overgrote meerderheid onverrijkte tekst gewoon kan doorzoeken. Complexere zoekopdrachten kunnen alleen worden uitgevoerd met verrijkte teksten, en juist daarom is deze hele simpele zoekopdracht nog steeds heel erg essentieel. Het is verwacht dat de hoeveelheid verrijkte teksten in de toekomst groter is.
Stap 4
We gaan naar het tabblad ‘Tijdlijn’. Wanneer deze pagina geladen is krijg je een overzicht van het absolute aantal hits per collectie. Zoals het er hier naar uitziet lijkt het alsof de KB Kranten het in de 18de en 19de eeuw erg veel over paarden hadden, terwijl er in de verschillende collecties van de 20ste eeuw toch minder over geschreven werd. Dit is natuurlijk een vertekend beeld. Misschien zijn er wel veel meer documenten in de collectie van de KB Kranten. Om een beter overzicht te krijgen moeten we naar de relatieve tijdlijn kijken. Klik op het vakje ‘Hits / aantal woorden in gevonden documenten per jaar’. Als je dezelfde varianten hebt gekozen als ik, krijg je onderstaande tijdlijn.
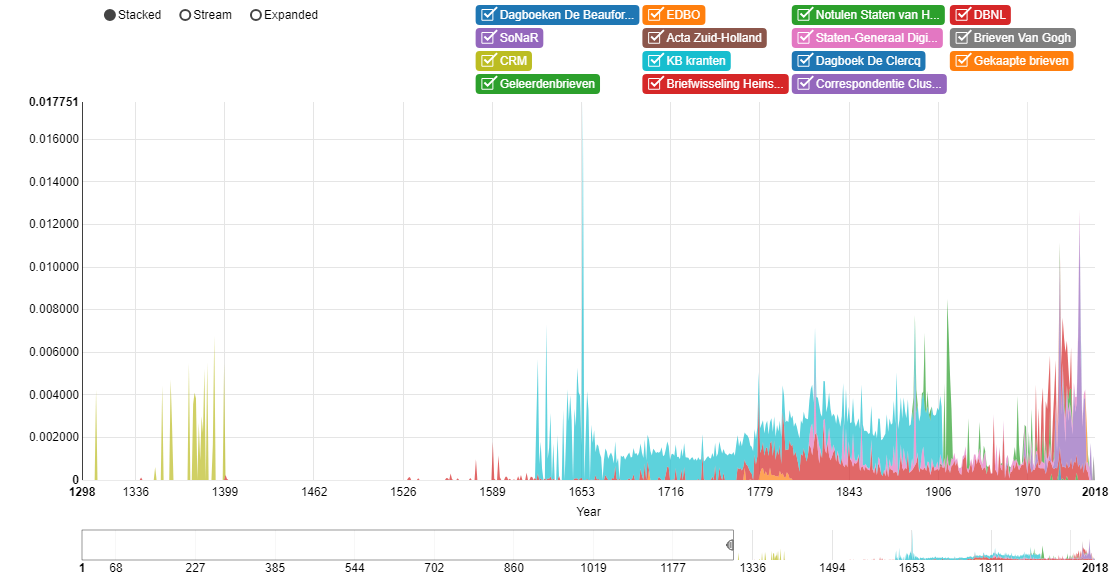
Nog steeds zijn de KB Kranten aan het domineren wat betreft de frequentie van het woord ‘paard’, maar nu is die aanname ergens op gebaseerd. Naar mate er meer collecties worden toegevoegd aan Nederlab wordt dit overzicht completer en completer. Mocht je je zoekopdracht willen beperken tot een bepaalde periode, dan kan de Tijdlijn ook goed dienen als verkenningsopdracht om te zien welke periode het meest interessant kan zijn voor je zoekopdracht.
Stap 5
Ga naar ‘Statistieken’. Klik hier op ‘Toon’, waarna je een overzichtje als die hieronder zult tegenkomen. Dit overzicht bestaat vooral uit trivia, zoals een maximaal aantal hits per document, of een minimaal aantal woorden per document.

Stap 6
Bij ‘Frequentielijsten’ kun je zien welke woorden, lemma’s, woordsoorten, of entities er het meeste voorkomen in de gevonden documenten. Let wel, deze zoekopdracht negeert de query compleet, en zal alle woorden in de documenten meenemen. Laten we er voor de oefening voor kiezen om alle woorden van tenminste drie letters, beginnend met een ‘b’ op te sommen. Mocht je benieuwd zijn hoe vaak er over een merrie wordt gepraat in deze documenten, dan zou je ook op dat woord kunnen zoeken hier, maar dat zou natuurlijk ook kunnen door de resultaten als corpus op te slaan en dan opnieuw te zoeken (meer daarover in volgende tutorials). Er kan op gevonden geklikt worden om ze in context tegen te komen.

Stap 7
Tot slot kan het nog interessant zijn om te zien welke varianten er nou het meest gebruikt zijn. Hier hebben we eigenlijk ook een frequentielijst voor nodig, maar dan eentje die exclusief naar de hits kijkt en de rest van de documenten negeert. Die functie heet ‘Groeperingen’. Ga daarheen en groepeer op ‘woord’ om deze lijst te genereren. Deze functie is heel erg zwaar, en als we teveel resultaten hebben, dan zal deze opdracht niet slagen. Mocht je dit meemaken, dan kun je dat verhelpen door het zoekveld te beperken. In onderstaand plaatje is alleen gezocht binnen DBNL, en niet in alle collecties, omdat dat simpelweg te veel was.
